
In this study, Prof. Madhu Viswanathan and Prof. Sumeet Kumar created a segmentation and targeting strategy based on data and connections of the audience tribes on Social Media platforms using Machine Learning to identify consumer segments for products with passionate followers.
1: Agenda
The goal is to create segmentation and targeting strategy based on audience tribes. To do so, one must distinguish between brands that are also tribes and brands which may not have a tribal following (Harley vs Colgate). In this paper, we will focus on brands that have a potential tribal following. The task in this setting can be straightforward if we look at individuals who are currently associated with the brand. The challenge would be in identifying tribal language, tribe leaders, and community members. To do so, we will follow the following steps.
1. Segmentation – Identifying an audience tribe
a) Brands with tribes can be identified based on their association with the brand name
b) Identify people that comment on these issues.
c) Develop a tribe lexicon based on these topics
d) Identify networks and membership in these tribes (active vs passive)
e) Identify associated topics
f) Output – people associated with the tribe, symbols associated with the tribe, content/topics associated with the tribe.
2: Targeting – Identifying the message and people to target
We now talk in detail about the methodology that was implemented to identify tribes. We will focus on two brands – Harley Davidson and Royal Enfield to illustrate our methodology.
3: Methodology
On Social Media (SM), people connect to other people for many reasons. The connections could be based on their family relationships, profession, passion, or beliefs. These connections influence their choices, and therefore a company trying to reach potential customers can use these connections to better understand users’ preferences. However, finding preferences based on these connections is not straightforward. One way to utilize these connections is by segmenting them into coherent groups. In this research, we propose a method to discover such segments (see Fig. 1).
In the proposed method, we first collect data based on the brand name or the company name. Though that data could be obtained from any public pages of the brand, we only use Tweets to simplify the illustration for this article. The data is then used to extract active users for whom we obtain additional profile/post information and their connections. Using users’ text and user connections, we use machine learning (ML) to find segments. Many ML approaches could be used for segmenting users based on their data and connections. Again, for simplicity, we use ‘topic modeling’ which has been a popular method for quite some time. In Fig. 1, we show how topic modeling could be used to find the topics of interest to obtain related consumer segments and their associated preferences.
For illustration, let’s take the example of Harley Davidson, an American motorcycle manufacturer. We know that Harley Davidson (HD) has a fan following. By exploring the tweets of user’s discussing HD, we can obtain different user segments. Based on the results obtained using our proposed method, it’s easy to find that Harley Davidson users are ad- venturous in nature (see Fig. 2), i.e., they are a part of a segment called ‘adventure seekers’. However, on closer inspection, we could also find other counter-intuitive segments. We find that many HD fans are also family-oriented, i.e., they display strong family bonds in their profile. In Fig. 2, we show segments using data obtained from Twitter users discussing HD. In the figure, one can observe words like ‘lover’, and ‘father’ that indicates preferences for solid family bonding. The resulting segments suggest that finding the right segments, even for a brand with fan-following, is not apparent, and further research could lead to new insights, both for traditional and non-traditional companies.
Note these segments would differ for different companies. Even for another motorcycle manufacturer, we would expect the segments to be different. To illustrate this, we explore ‘Royal Enfield’, a similar motorcycle company based in India. Using the proposed approach, we obtain the segments of users discussing ‘Royal Enfield’ on Twitter. As seen in Fig. 3, besides travelers, also find ‘photographers’. More interestingly, we also find ‘foodie’, ‘healthy’, and ‘non-vegetarian’, a food-based segment that is very different from the expected traveler-based segment.
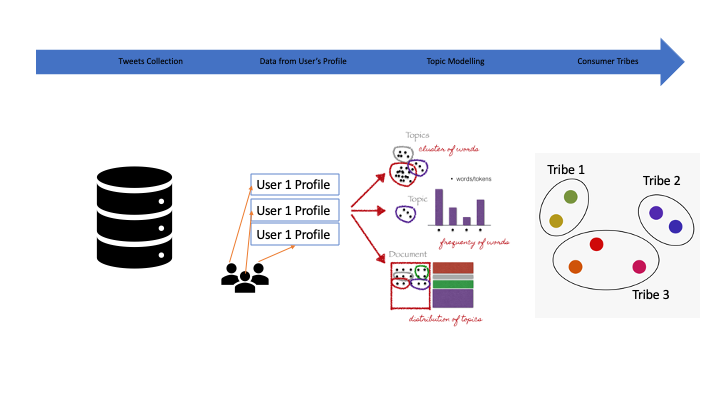
Figure 1: Steps to obtain user segments: We first collect the data based on the brand or company names. The data is then used to extract active users for whom we obtain the profile/post information and users’ connections. Using users’ text and users’ connections, we use machine learning to find segments. For illustration, we show how topic modeling could be used to find the topics of interest and related consumer segments and associated preferences.
4: Conclusion In this short article, we discussed how to identify consumer segments for products that have passionate followers like Harley Davidson and Royal Enfield. What would be interesting is to find ways to find such segments for a non-fan-following company. We leave this discussion for the next article. Our methodology as stated before can not only identify associated topics but also identify networks of passive consumers.

Figure 2: A word cloud generated with words in the Twitter profile of users discussing Harley Davidson. As visible, ‘travel’, ‘motorcycle’ and ‘adventure’, these users also commonly mention ‘Father’, ‘love’ and ‘life’ indicating family as their other important priority. Some other interests are ‘books’ and ‘music’.

Figure 3: A word cloud generated with words in Twitter profiles of users discussing Royal Enfield. As visible, ‘traveler’, ‘biker’ and ‘ride’, these users also commonly mention ‘photographer’, ’blogger’ and ‘healthy’, ‘foodie’ indicating their other important priorities.